

Does anybody know of a study/paper/webpage that shows what phonemes actually look/sound like as sound waves?
Also, with such waves in mind, one could also compare waves and define a difference/distance between two sounds, and then compare the distance between pairs of similar phonemes that merge into a single phoneme. Or maybe tests could be done that test the speed of recognition of phonemes. Have either of these things been done before?
The Sound Waves of Sounds
-
Ser

- Smeric

- Posts: 1542
- Joined: Sat Jul 19, 2008 1:55 am
- Location: Vancouver, British Columbia / Colombie Britannique, Canada
Re: The Sound Waves of Sounds
Soundwaves, which are graphs that plot volume (intensity) vs. time, aren't very useful because you can't quite appreciate anything but volume—linguists use spectrograms instead (graphs that plot frequency vs. time, with intensity in frequencies marked with bolder or lighter lines) as well as power spectra (graphs that plot intensity vs. frequency at a given point in time).
And that kind of work has been done plenty of times by phoneticians. TheGoatMan even made a thread one day commenting on some project he had participated in as an undergraduate involving phonemes in Shanghainese. You can see a couple power spectra he pulled off showing that, perceptually at least, a syllable-initial [ɕ] is practically identical to a [ɕ]-like sound that occurs after /pʰ/ before /i/ (which another user says it's better described as [ʲ], [ɹ̝̊] or [θ̠ ]).
And that kind of work has been done plenty of times by phoneticians. TheGoatMan even made a thread one day commenting on some project he had participated in as an undergraduate involving phonemes in Shanghainese. You can see a couple power spectra he pulled off showing that, perceptually at least, a syllable-initial [ɕ] is practically identical to a [ɕ]-like sound that occurs after /pʰ/ before /i/ (which another user says it's better described as [ʲ], [ɹ̝̊] or [θ̠ ]).

Re: The Sound Waves of Sounds
I tried doing some things with spectrograms, but since I only know what I have found on the internet, I had a lot of trouble getting anything meaningful from it, because the values from the program I was using didn't seem to match up with the values I was finding on the Internet. Can anyone provide some advice on how to to create and measure spectrograms to determine vowel qualities and so forth?

Re: The Sound Waves of Sounds
Praat maybe?Terra wrote:Does anybody know of a study/paper/webpage that shows what phonemes actually look/sound like as sound waves?
Also, with such waves in mind, one could also compare waves and define a difference/distance between two sounds, and then compare the distance between pairs of similar phonemes that merge into a single phoneme. Or maybe tests could be done that test the speed of recognition of phonemes. Have either of these things been done before?
http://www.fon.hum.uva.nl/praat/
Waves in the Spanish wikipedia article for Praat.
Waves in the Portuguese wikipedia article.
An extended and updated version of Mentors and Students concept is available here.
Re: The Sound Waves of Sounds
Yes, this is the kind of thing that I'm looking for. I didn't know the term "spectrograms".Soundwaves, which are graphs that plot volume (intensity) vs. time, aren't very useful because you can't quite appreciate anything but volume—linguists use spectrograms instead (graphs that plot frequency vs. time, with intensity in frequencies marked with bolder or lighter lines) as well as power spectra (graphs that plot intensity vs. frequency at a given point in time).
Interesting, interesting.And that kind of work has been done plenty of times by phoneticians. TheGoatMan even made a thread one day commenting on some project he had participated in as an undergraduate involving phonemes in Shanghainese. You can see a couple power spectra he pulled off showing that, perceptually at least, a syllable-initial [ɕ] is practically identical to a [ɕ]-like sound that occurs after /pʰ/ before /i/ (which another user says it's better described as [ʲ], [ɹ̝̊] or [θ̠ ]).


Re: The Sound Waves of Sounds
I did some of this stuff at university. Praat's a really good tool for it, but it has quite a steep initial learning curve. I haven't really done that much meaningful with it since I left, unfortunately, so the skills are being forgotten...
It''s worth noting that you can only really deduce meaningful information about vowels with formant analysis – voiced sonorants have some information that you can see on the spectrogram, and with plosives you can measure voice onset time for a scientifically accurate measure of aspiration or voicing, but voiceless fricatives especially are particularly bad for really not being able to see anything, since it's completely irregular. there tends to be some concentration in the high frequencies but you can't "read" what particular sonud it is like you can sort of do with vowels (same with plosives). Obviously the sounds must be different, because we hear a difference, but I'm not sure what that difference is, auditorially speaking. Also, rhoticity is said to decrease the third formant, which isn't otherwise involved in vowel production, but I seem to remember that being quite controversial when I was taught it. I can't really remember, tbh.
It''s worth noting that you can only really deduce meaningful information about vowels with formant analysis – voiced sonorants have some information that you can see on the spectrogram, and with plosives you can measure voice onset time for a scientifically accurate measure of aspiration or voicing, but voiceless fricatives especially are particularly bad for really not being able to see anything, since it's completely irregular. there tends to be some concentration in the high frequencies but you can't "read" what particular sonud it is like you can sort of do with vowels (same with plosives). Obviously the sounds must be different, because we hear a difference, but I'm not sure what that difference is, auditorially speaking. Also, rhoticity is said to decrease the third formant, which isn't otherwise involved in vowel production, but I seem to remember that being quite controversial when I was taught it. I can't really remember, tbh.
Re: The Sound Waves of Sounds
Anyway, quick theory lesson before I go to bed: formants are harrmonic frequencies that have stronger concentrations. The harmonics are integer multiples of each other, and the frequency of the first harmonic determines the pitch of a sound. If you make a graph of the frequencies of a sound, you will see many peaks and troughs at regular intervals, and they will as a group go up and down in clusters (it's reminiscent of a graph of AM radio, except that the scale is frequency vs amplitude, rather than time vs amplitude). A spectrogram is, in its ideal form, infinitesimal frequency graphs stacked up side by side, with the amplitude of those multiple peaks I mentioned represented by darker patches – formants are where these dark patches come in bands. In practice the infinitesimal part is infeasible, and actually you have to sample a small area around each target time in order to find out the frequencies (in this sense, reminiscent of ∂x/∂y). You have to select the size of this sampling area. Praat should have a default, but play around with it and you'll get weird smearing effects.
And the most mindboggling aspect of formants is that the first two are corellated so well with the vowel height and front/back scales. Great for doing measurements.
And the most mindboggling aspect of formants is that the first two are corellated so well with the vowel height and front/back scales. Great for doing measurements.
-
Ser
- Smeric
- Posts: 1542
- Joined: Sat Jul 19, 2008 1:55 am
- Location: Vancouver, British Columbia / Colombie Britannique, Canada
Re: The Sound Waves of Sounds
It's/it was controversial likely because it's also affected by rounding... (I haven't heard of it being controversial, but what do I know.)finlay wrote:Also, rhoticity is said to decrease the third formant, which isn't otherwise involved in vowel production, but I seem to remember that being quite controversial when I was taught it. I can't really remember, tbh.

Re: The Sound Waves of Sounds
With plosives, though, aren't the sounds they make differentiated by the formants around them? Like velars make f2 and f3 come together, and bilabials make all of the formants lower, and alveolars make my head hurt. If that's the case, how does one hear a series of three plosives in a row?


Re: The Sound Waves of Sounds
Sounds about accurate, though i don't think i really studied this properly. To distinguish them, the important part is the release, as without that you'd hear it going into one plosive and out another - which is basically exactly what the African coarticulated plosives are.Vuvuzela wrote:With plosives, though, aren't the sounds they make differentiated by the formants around them? Like velars make f2 and f3 come together, and bilabials make all of the formants lower, and alveolars make my head hurt. If that's the case, how does one hear a series of three plosives in a row?
Re: The Sound Waves of Sounds
It looks like we are re-inventing acoustic phonetics! Wonderful.
To answer Geoff's original question, yes, there have been many many many studies, papers, dissertations, and so on, about the physical (i.e. acoustic) manifestation of speech sounds. There have likewise been many on the properties of the signal that lead to robust or degraded speech perception.
First, though, it might be worthwhile to consider a little history. Acoustic phonetics and speech perception really got rolling in the late 50s and early 60s, particularly in Haskins Labs. One of the early discoveries has already been mentioned - vowels are cued by the frequencies of the first and second formant. We can synthesize different vowels by changing what the formant frequencies are. Another the early discoveries is what Vuvuzela mentioned - that stops are cued by the formant transitions on the vowels around them. Here is an example:
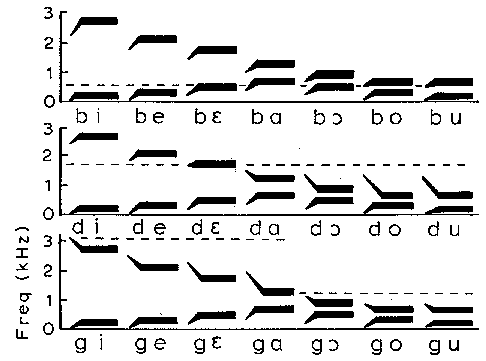
For those of you who don't know what we're looking at, I'm going to assume that you've read the earlier descriptions in this thread of a spectrogram. In the above image, the x-axis is time and the y-axis is frequency. The lines indicate formants changing over time. The top row shows labial stops, moving into different vowels. We can see that the formant frequency tends to rise as the stop is released and the vowel begins. The alveolars and the velars all show different patterns, but there is a functional unity within each category. We can imagine that each place of articulation has a frequency "locus" that it roughly starts at, and the frequency then rises or falls to get to the steady-state of the vowel.
These and other findings lead to a 'cue-based' model of speech perception. If I hear a high first formant, aha! I know I'm hearing a low vowel. However, we know that people can't be attending to just the absolute values that they hear - for instance, a child's [a] and a man's [a] both sound like an /a/, despite them being very acoustically different. There have been experiments where people perceived different sounds or words, despite being presented with the same acoustic material: the context was different so their perception changed.
The cue-based model was really shown to be naive, though, in the 90s. For example, in one study, listeners were presented with recordings of everyday sentences. The sentences had been altered so that only an extremely narrow frequency band remained - say, just the material between 1750Hz and 2800Hz. Everything else was silent. However, the listeners performed above chance in perceiving the sentences correctly, despite many of the cues not being present. It seems that people are able to integrate a whole variety of acoustic information, even if it's not a "primary cue".
The existence of acoustic cues is worth pondering - just because we can find an acoustic feature that regularly co-occurs with some phoneme doesn't mean that language users are actually attending to that cue. There is some evidence that different languages rely on different acoustic cues in their perception of certain contrasts, despite the sounds in question being very similar or the same. This fact makes the calculation of a quantitative metric of distance or difference, as suggested in the original post, quite hard to do, because we don't know what cues or features to base such a metric on, and we don't know whether those cues or features are even psychologically valid.
However, there is a far easier way to assess perceptual confusability, and that is simply to run perception tests. Get a group of subjects, play them some sounds (presumably in the presence of some white noise or a similarly difficult listening environment) and ask them to categorize them. The mistakes they make will inform us what sounds are easily confusable - for instance, /th/ and /f/ are easily confusable; /f/ and /k/ are not. There is research right now (as in, hot-off-the-press) that suggests that the likelihood of a historical merger happening is linked to not only the perceptual similarity of the two sounds in question, but also to the functional load between the two sounds. Similarly, other hot-off-the-press research suggests that languages prefer lexical minimal pairs where the pair of sounds is minimally confusable (shop vs pop), and disprefer lexical minimal pairs where the sounds are highly confusable (thought vs fought). (Put in another way, highly confusable minimal pairs are attested less often than we would expect by chance, and less confusable minimal pairs are attested more often than we would expect by chance.)
If anyone is interested in learning more about acoustic phonetics in general, I recommend Keith Johnson's textbook as a good resource.
To answer Geoff's original question, yes, there have been many many many studies, papers, dissertations, and so on, about the physical (i.e. acoustic) manifestation of speech sounds. There have likewise been many on the properties of the signal that lead to robust or degraded speech perception.
First, though, it might be worthwhile to consider a little history. Acoustic phonetics and speech perception really got rolling in the late 50s and early 60s, particularly in Haskins Labs. One of the early discoveries has already been mentioned - vowels are cued by the frequencies of the first and second formant. We can synthesize different vowels by changing what the formant frequencies are. Another the early discoveries is what Vuvuzela mentioned - that stops are cued by the formant transitions on the vowels around them. Here is an example:
For those of you who don't know what we're looking at, I'm going to assume that you've read the earlier descriptions in this thread of a spectrogram. In the above image, the x-axis is time and the y-axis is frequency. The lines indicate formants changing over time. The top row shows labial stops, moving into different vowels. We can see that the formant frequency tends to rise as the stop is released and the vowel begins. The alveolars and the velars all show different patterns, but there is a functional unity within each category. We can imagine that each place of articulation has a frequency "locus" that it roughly starts at, and the frequency then rises or falls to get to the steady-state of the vowel.
These and other findings lead to a 'cue-based' model of speech perception. If I hear a high first formant, aha! I know I'm hearing a low vowel. However, we know that people can't be attending to just the absolute values that they hear - for instance, a child's [a] and a man's [a] both sound like an /a/, despite them being very acoustically different. There have been experiments where people perceived different sounds or words, despite being presented with the same acoustic material: the context was different so their perception changed.
The cue-based model was really shown to be naive, though, in the 90s. For example, in one study, listeners were presented with recordings of everyday sentences. The sentences had been altered so that only an extremely narrow frequency band remained - say, just the material between 1750Hz and 2800Hz. Everything else was silent. However, the listeners performed above chance in perceiving the sentences correctly, despite many of the cues not being present. It seems that people are able to integrate a whole variety of acoustic information, even if it's not a "primary cue".
The existence of acoustic cues is worth pondering - just because we can find an acoustic feature that regularly co-occurs with some phoneme doesn't mean that language users are actually attending to that cue. There is some evidence that different languages rely on different acoustic cues in their perception of certain contrasts, despite the sounds in question being very similar or the same. This fact makes the calculation of a quantitative metric of distance or difference, as suggested in the original post, quite hard to do, because we don't know what cues or features to base such a metric on, and we don't know whether those cues or features are even psychologically valid.
However, there is a far easier way to assess perceptual confusability, and that is simply to run perception tests. Get a group of subjects, play them some sounds (presumably in the presence of some white noise or a similarly difficult listening environment) and ask them to categorize them. The mistakes they make will inform us what sounds are easily confusable - for instance, /th/ and /f/ are easily confusable; /f/ and /k/ are not. There is research right now (as in, hot-off-the-press) that suggests that the likelihood of a historical merger happening is linked to not only the perceptual similarity of the two sounds in question, but also to the functional load between the two sounds. Similarly, other hot-off-the-press research suggests that languages prefer lexical minimal pairs where the pair of sounds is minimally confusable (shop vs pop), and disprefer lexical minimal pairs where the sounds are highly confusable (thought vs fought). (Put in another way, highly confusable minimal pairs are attested less often than we would expect by chance, and less confusable minimal pairs are attested more often than we would expect by chance.)
If anyone is interested in learning more about acoustic phonetics in general, I recommend Keith Johnson's textbook as a good resource.
The man of science is perceiving and endowed with vision whereas he who is ignorant and neglectful of this development is blind. The investigating mind is attentive, alive; the mind callous and indifferent is deaf and dead. - 'Abdu'l-Bahá
-
Radius Solis

- Smeric
- Posts: 1248
- Joined: Tue Mar 30, 2004 5:40 pm
- Location: Si'ahl
- Contact:
Re: The Sound Waves of Sounds
Awesome, Rory, that's all good stuff to know, for those like me who haven't studied phonetics as well as we should. Thanks!
I've long gotten the impression that while syntactic theories may have all the crystalline structure of math, when you try to nail phonetics down good and hard you end up with all the mess and sticky theoretic goo that'd you'd expect of biology.
That's an interesting point. The first thought I'd had about Vuvu's post was: if distinguishing plosives were only a matter of their effect on surrounding formants, we wouldn't be able to tell them apart when pronounced in isolation. And, of course, the McGurk effect demonstrates that even visual cues play into our perception of speech sounds. Given that, there could well be a whole zoo of things that help us identify [k] as [k].It seems that people are able to integrate a whole variety of acoustic information, even if it's not a "primary cue".
I've long gotten the impression that while syntactic theories may have all the crystalline structure of math, when you try to nail phonetics down good and hard you end up with all the mess and sticky theoretic goo that'd you'd expect of biology.
Re: The Sound Waves of Sounds
You're welcome! Sometimes I forget that not everyone here has ~8 years of phonetic theory and practical training under their belts.Radius Solis wrote:Awesome, Rory, that's all good stuff to know, for those like me who haven't studied phonetics as well as we should. Thanks!
Absolutely - visual information is a huge help. Another point that I forgot to mention is that stop place information is also contained in the spectral composition of the burst phase itself.That's an interesting point. The first thought I'd had about Vuvu's post was: if distinguishing plosives were only a matter of their effect on surrounding formants, we wouldn't be able to tell them apart when pronounced in isolation. And, of course, the McGurk effect demonstrates that even visual cues play into our perception of speech sounds. Given that, there could well be a whole zoo of things that help us identify [k] as [k].It seems that people are able to integrate a whole variety of acoustic information, even if it's not a "primary cue".
Some distinctions are hard to see on spectrograms or waveforms, which reminds us that spectrograms are simply tools that we use to try and understand how information is encoded in sound waves. There are many other ways to analyze sound waves (e.g. amplitude envelopes, or cepstral coefficients), and they're all mere approximations at best of what the human auditory cortex is actually doing.
(I might contest that human syntactic behavior is "crystalline", but that's a different discussion for a different day. And psygnisfive would probably swoop in here and tell me I'm wrong.) Yes, phonetic data is notoriously variable and messy; it is a real wonder that any of us can understand each other at all. It's relatively easy to understand sound waves on a physical level - that's what acousticians and signal processors have been doing for decades - but the really interesting questions are at the edges of acoustics - the process by which we transform some psychological schema or phoneme string into a series of coordinated articulatory gestures, producing sound; and the process by which we receive incoming waves, strip out the irrelevant parts (e.g. background noise or even another person talking), segment it into pieces, and comprehend what is actually being said. Especially since some of these abilities - such as basic audition - are presumably very ancient (evolutionarily speaking), while some - such as phoneme recognition - are presumably very new. Other abilities show remarkable similarities with higher cognitive processes in other modalities - consider the examples of temporal induction of speech on this page and compare with the "picket fence effect", which is the ability to visually perceive a house as a coherent whole even if parts of the house are obscured by a picket fence.I've long gotten the impression that while syntactic theories may have all the crystalline structure of math, when you try to nail phonetics down good and hard you end up with all the mess and sticky theoretic goo that'd you'd expect of biology.
Gosh, science is so exciting!
The man of science is perceiving and endowed with vision whereas he who is ignorant and neglectful of this development is blind. The investigating mind is attentive, alive; the mind callous and indifferent is deaf and dead. - 'Abdu'l-Bahá
Re: The Sound Waves of Sounds
you're reminding me that I need to actually go back and study this stuff properly again. also that's not geoff, it's just someone else with a female avatar. i haven't seen geoff around here in many months.
-
Salmoneus

- Sanno

- Posts: 3197
- Joined: Thu Jan 15, 2004 5:00 pm
- Location: One of the dark places of the world
Re: The Sound Waves of Sounds
Humans are similarly awesome with music. We can pick out a tune in the midst of a great mass of noise. We can immediately recognise music from the smallest cues - there have been times when I've heard just a single opening chord and known instantly what the following notes were going to be. And we can extrapolate bits of music even though the rules they conform to are vague and uncodified - if I listen to a piece of common practice era music that I haven't heard before and it suddenly stops, chances are I'll have a good shot at guessing what happens next, for at least a couple of seconds, though I certainly don't have enough music theory to explain WHY I'm expecting exactly that to happen.Rory wrote:You're welcome! Sometimes I forget that not everyone here has ~8 years of phonetic theory and practical training under their belts.Radius Solis wrote:Awesome, Rory, that's all good stuff to know, for those like me who haven't studied phonetics as well as we should. Thanks!
Absolutely - visual information is a huge help. Another point that I forgot to mention is that stop place information is also contained in the spectral composition of the burst phase itself.That's an interesting point. The first thought I'd had about Vuvu's post was: if distinguishing plosives were only a matter of their effect on surrounding formants, we wouldn't be able to tell them apart when pronounced in isolation. And, of course, the McGurk effect demonstrates that even visual cues play into our perception of speech sounds. Given that, there could well be a whole zoo of things that help us identify [k] as [k].It seems that people are able to integrate a whole variety of acoustic information, even if it's not a "primary cue".
Some distinctions are hard to see on spectrograms or waveforms, which reminds us that spectrograms are simply tools that we use to try and understand how information is encoded in sound waves. There are many other ways to analyze sound waves (e.g. amplitude envelopes, or cepstral coefficients), and they're all mere approximations at best of what the human auditory cortex is actually doing.
(I might contest that human syntactic behavior is "crystalline", but that's a different discussion for a different day. And psygnisfive would probably swoop in here and tell me I'm wrong.) Yes, phonetic data is notoriously variable and messy; it is a real wonder that any of us can understand each other at all. It's relatively easy to understand sound waves on a physical level - that's what acousticians and signal processors have been doing for decades - but the really interesting questions are at the edges of acoustics - the process by which we transform some psychological schema or phoneme string into a series of coordinated articulatory gestures, producing sound; and the process by which we receive incoming waves, strip out the irrelevant parts (e.g. background noise or even another person talking), segment it into pieces, and comprehend what is actually being said. Especially since some of these abilities - such as basic audition - are presumably very ancient (evolutionarily speaking), while some - such as phoneme recognition - are presumably very new. Other abilities show remarkable similarities with higher cognitive processes in other modalities - consider the examples of temporal induction of speech on this page and compare with the "picket fence effect", which is the ability to visually perceive a house as a coherent whole even if parts of the house are obscured by a picket fence.I've long gotten the impression that while syntactic theories may have all the crystalline structure of math, when you try to nail phonetics down good and hard you end up with all the mess and sticky theoretic goo that'd you'd expect of biology.
Gosh, science is so exciting!
Blog: [url]http://vacuouswastrel.wordpress.com/[/url]
But the river tripped on her by and by, lapping
as though her heart was brook: Why, why, why! Weh, O weh
I'se so silly to be flowing but I no canna stay!
But the river tripped on her by and by, lapping
as though her heart was brook: Why, why, why! Weh, O weh
I'se so silly to be flowing but I no canna stay!