
First of all, I know that there are many, many sound changers online already. The goal of this project is not to make the best sound change applier, but to make a sound change supplier that supports lots of features and is also compatible with zompist's SCA2 - as mentioned above, there are many very good sound changers already, but their format is quite different to the SCA's (e.g. going from P/B/_ *reaction -> reagdion to * <ustop> <vstop> _ ! reaction -> reagdion) and it could be hard to completely change how you write sound change rules.
Since I had some time, I decided to create a sound change applier that does exactly that. Thus, I present the exSCA (Extended Sound Change Applier), which you can get from here (no mac version yet, though I'm working on it - sorry!), supporting:
- Everything that the SCA2 does (except the wildcard)
- Syllabification using regexes
- Automatic affixer
- Categories within categories
- Syntax highlighting
- Opening and saving sound changes and lexicon
- Writing custom sound changes in Python
- Everything is typable using an ordinary computer keyboard - 2 is replaced by > (I haven't added glosses or the wildcard yet)
- The wildcard (in the meantime you can implement it using Python - at the bottom of the post is some code you can copy into the program)
- Backtracking (so a/b/_(C)C would not apply to the word 'ap' because it would interpret the 'p' as part of the (C))
- The Edit menu (in the meantime, use Ctrl-C, Ctrl-X and Ctrl-V).
New Features
ASCII
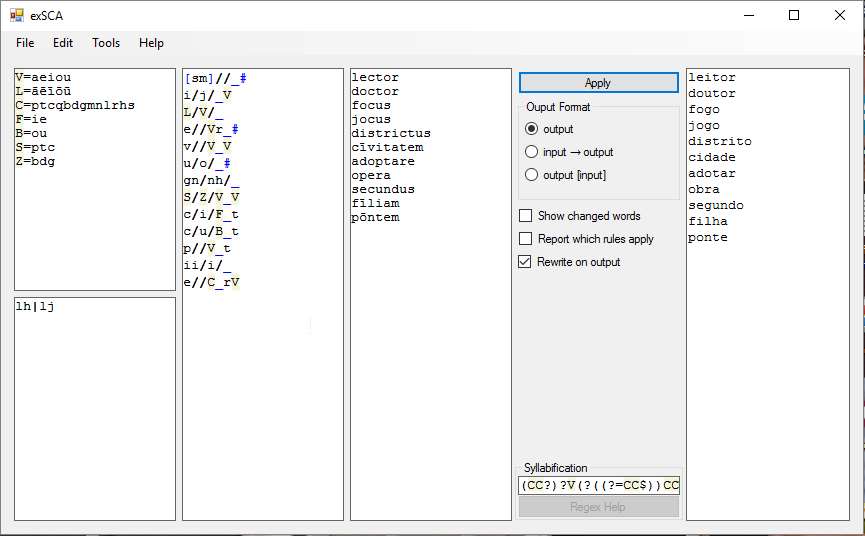
The SCA2 uses 2 to represent duplication. The exSCA replaces this with the character >, which can be typed much more easily.
Syllabification
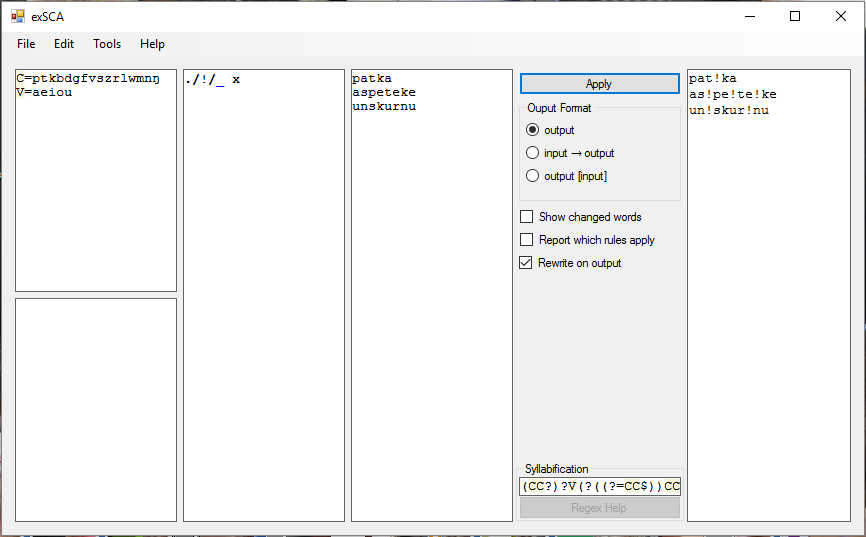
Many people have complained on this forum about the lack of syllabification in the SCA and SCA2. In the exSCA, I have included regex syllabification, accessed by putting an 'x' in front of the rule, separated from it by a single space, which adds a . at each syllable boundary. Its main purpose would probably be to not let sound changes work across syllable boundaries (e.g. st/ss/_ x, when applied to a word like aste, would syllabificate it as as.te and not match anything because the sequence of characters is s.t, not st).
Syllabification regexes
The syllabification algorithm operates using regexes: the program finds all the parts of the word that matches the regex, then takes them and sticks a . between them. (Note: One consequence of the way the algorithm is implemented is that if you provide a regex that doesn't match all of the word, the word will get scrambled!) The regexes themselves are ordinary .NET Framework regexes, with one exception: you can use category names in them (e.g. using the definitions C=ptkbdg and V=aeiou, the regex C?V will be turned into [ptkbdg]?[aeiou]). These will have a beige background.
The default regex is an expression that matches (C)V(C(C)) words, leveraging the regex capabilities of the .NET Framework. Below I provide some regexes for several different syllable structures:
(C)V: C?V
(C)V(C): C?V(((?=CC))C|(((?=C$))C|))
Onset-Rime-Coda (as in Chinese): There are two variations of this one, depending on how you want to parse a VCVC word (e.g. anaŋ).
If you want it to parse as VC-VC (e.g. an-aŋ): O?RC?
If you want it to parse as V-CVC (e.g. a-naŋ): O?R(((?=O))|(((?=C))C|))
(C)(C)V(C): (CC?)?V(((?=CC))C|(((?=C$))C|))
Affixer (Decliner/Conjugator)
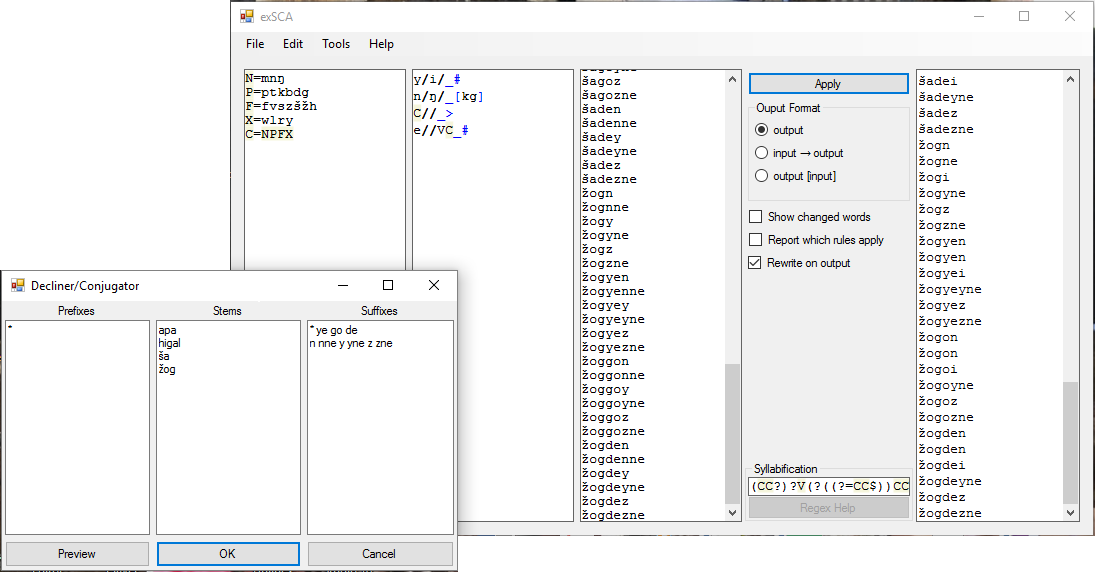
The automatic affixer (called the Decliner/Conjugator in the program, and accessed via Tools->Decliner/Conjugator or Ctrl-J) is a utility I created to help run declensions or conjugations through the exSCA quickly. When you open it up there are three textboxes: a prefixes one, a stems one and a suffixes one. (No infix support yet, sorry!)
The affixer works by using slots. Each line you put into each textbox counts as one slot. Each slot is composed of several parts, each separated by one space. When you press OK, the words textbox in the main window is filled with all combinations of the different slots with exactly one affix from each slot in each word. You can use an * (asterisk) to denote that the slot is optional - or, to be precise, the empty affix. Each textbox (except the stems textbox) by default contains one * (asterisk). If you keep a textbox empty, you shouldn't remove it. (You can, but then the affixer won't work.) Putting this all together, here is some sample input to the affixer and its output:
Code: Select all
Prefixes Stems Suffixes
* apa ne * in
higal ye go * de
ša n nne y yne z zne
Produces an output of:
apaneyen
apaneyenne
apaneyey
apaneyeyne
apaneyez
apaneyezne
apanegon
apanegonne
apanegoy
apanegoyne
apanegoz
apanegozne
apanen
apanenne
apaney
apaneyne
apanez
.
.
.
šaindenne
šaindey
šaindeyne
šaindez
šaindezne
You can define categories that use other categories inside them - for instance:
Code: Select all
P=ptk
B=bdg
F=fsx
V=vzG
N=mnŋ
X=rlw
C=PBFVSZX
Python Sound Changes
EDIT: After version 2.0.0, exSCA does not support Python sound changes anymore. You can use regex rules instead, described in this post.
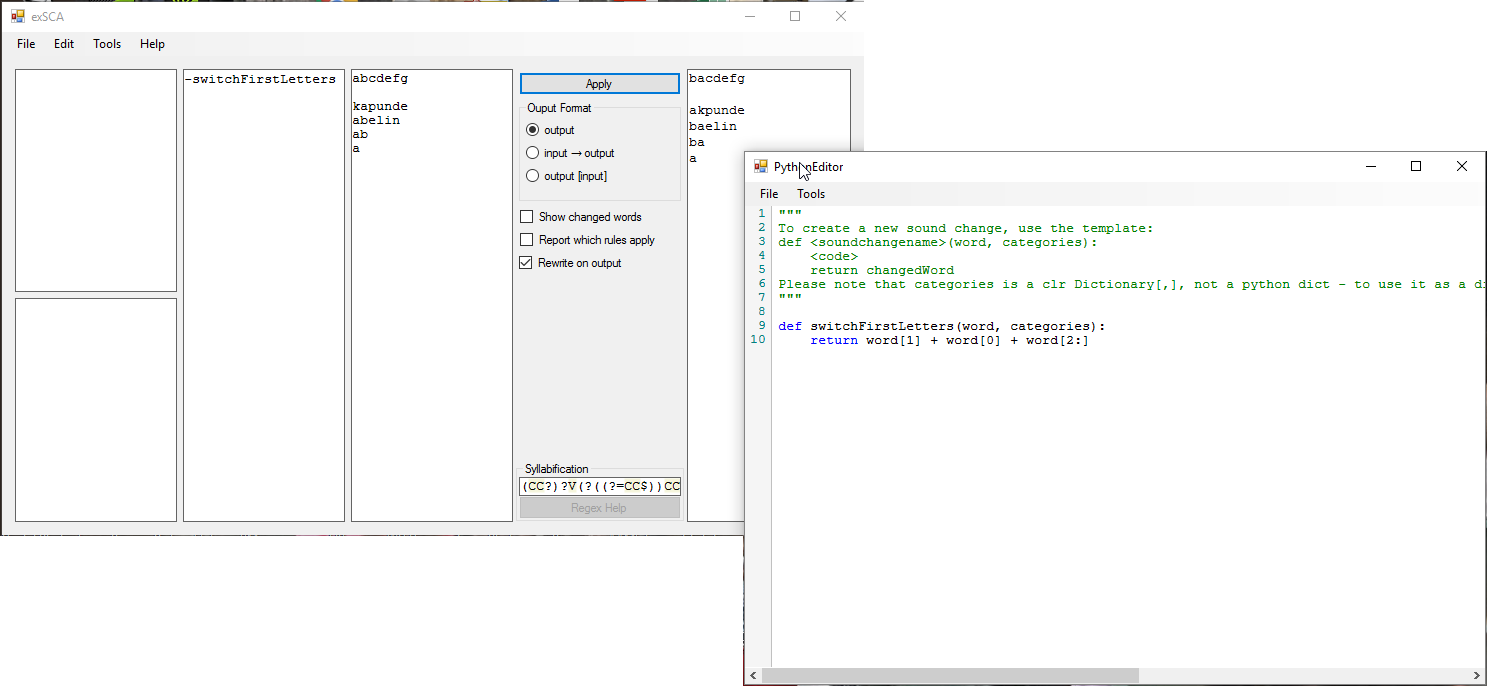
In my opinion, the most innovative feature of this sound change applier is that you can define your own sound changes using the Python (specifically, IronPython, which supports the clr or .NET Framework as well as everything in ordinary Python) programming language. You can open the Python editor from Tools -> Python Editor, or Ctrl-P. Note that you don't have to save your changes for them to work - you just switch between windows and your changes are applied automatically.
Each python sound change is a method of the form
Code: Select all
def <soundchangename>(word, categories):
<code>
return changedWord
To execute this sound change from the list of sound changes, go -<my_python_sound_change. For instance, to execute the python method called remove_consonant_clusters, go -remove_consonant_clusters.
One More Thing - a Replacement for the Wildcard
I didn't include the wildcard in the exSCA for three reasons:
- In most situations where the wildcard was used in the SCA2, it needed recursion, which the SCA2 didn't have, so in my opinion it was useless
- It is very hard to implement
- You can implement it in Python!
Code: Select all
# Executes TEXT_AFTER/REPLACEMENT_TEXT/TEXT_BEFORE..._
def python_wildcard(word, cats):
changedWord = word
scannedText = ""
before = "TEXT_BEFORE"
after = "TEXT_AFTER"
replacement = "REPLACEMENT_TEXT"
flag = False
i = 0
for c in changedWord:
scannedText += c
if flag == False:
if scannedText.endswith(before):
flag = True
scannedText = ""
else:
if scannedText.endswith(after):
changedWord = changedWord[:i - len(after) + 1] + replacement + changedWord[i + 1:]
i += 1
return changedWord
If you find any bugs (and there are probably lots), post them here and I'll try my best to fix them. Also, if you have a suggestion for a new feature, you post here too and I'll do my best to implement it.







